Within Feedback
Why Saying 70 Percent Changes Feedback
Putting a number on uncertainty turns vague judgement into feedback that can be checked across many predictions.
On this page
- Why vague forecasts are hard to learn from
- How probability estimates reveal calibration over time
- Simple ways to review batches of predictions
Page outline Jump by section
Introduction
Putting a numerical probability on a prediction changes confidence from a feeling into something that can be tested. Saying that an event is “likely” leaves no clear record of how confident you were. Saying there is a 70% chance creates a claim that can be evaluated across many forecasts. If, over time, events assigned a 70% probability occur about seven times out of ten, your confidence is well calibrated. If they occur far less or far more often, your judgement needs adjustment.
 This shift from vague language to explicit probabilities is one of the most effective feedback mechanisms for improving analytical thinking. It allows confidence itself—not just whether a prediction happened to be right or wrong—to become measurable. Forecasting research, decision science and weather forecasting have all shown that repeated probabilistic predictions make it possible to distinguish genuine judgement from overconfidence, underconfidence and luck. [Good Judgment+2ResearchGate]goodjudgment.comGood Judgment Superforecaster-Accuracy.pdfGood Judgment measures accuracy using the Brier score, a score that shows how far a forecast fell from the.Read more…
This shift from vague language to explicit probabilities is one of the most effective feedback mechanisms for improving analytical thinking. It allows confidence itself—not just whether a prediction happened to be right or wrong—to become measurable. Forecasting research, decision science and weather forecasting have all shown that repeated probabilistic predictions make it possible to distinguish genuine judgement from overconfidence, underconfidence and luck. [Good Judgment+2ResearchGate]goodjudgment.comGood Judgment Superforecaster-Accuracy.pdfGood Judgment measures accuracy using the Brier score, a score that shows how far a forecast fell from the.Read more…
Why vague forecasts are hard to learn from
Natural language is surprisingly imprecise. Different people attach different meanings to words such as “possible”, “probable” or “unlikely”. Even the same person may use them inconsistently from one decision to the next.
Imagine two analysts who both describe a policy outcome as “likely”. One secretly means about 60%; the other means 90%. If the event happens, both appear equally correct. If it fails, both appear equally mistaken. There is no way to discover whether either person’s confidence matched reality.
Probabilities solve this problem because they preserve information that would otherwise disappear. Instead of recording only whether a prediction succeeded, they record how strongly the forecaster expected each outcome. This richer record supports much better feedback over dozens or hundreds of predictions. [Wikipedia]WikipediaBrier scoreBrier score
How probability estimates reveal calibration over time
Calibration refers to the agreement between stated confidence and observed outcomes. It is not judged from one prediction but from many.
For example:
- Predictions given 90% confidence should prove correct roughly nine times out of ten.
- Predictions given 70% confidence should succeed about seven times out of ten.
- Predictions given 30% confidence should occur around three times out of ten.
No individual forecast can verify calibration because chance still plays a role. A 90% prediction can fail, just as a 10% prediction can succeed. Calibration only becomes visible when forecasts are grouped into confidence bands and compared with what actually happened. [Good Judgment]goodjudgment.comGood Judgment Superforecaster-Accuracy.pdfGood Judgment measures accuracy using the Brier score, a score that shows how far a forecast fell from the.Read more…
A well-calibrated forecaster therefore does not avoid uncertainty. Instead, they express uncertainty honestly and consistently enough that their long-run confidence matches reality.
This is a different quality from simply being accurate. Someone could always predict “50%” and avoid looking overconfident, yet provide little useful discrimination between likely and unlikely events. Good forecasting requires both calibration and the ability to distinguish stronger from weaker evidence. Proper scoring methods reward both qualities together. [arXiv]arxiv.orgarXiv"Calibeating": Beating Forecasters at Their Own GameSeptember 11, 2022…
Why scoring rules matter
Simply counting correct predictions is often misleading.
Consider two forecasters making the same binary prediction:
- Forecaster A predicts 51%.
- Forecaster B predicts 99%.
If the event occurs, both are technically correct. Yet Forecaster B expressed vastly greater confidence.
Proper scoring rules recognise this difference. One of the most widely used is the Brier score, introduced by Glenn Brier in 1950. It measures the squared difference between the predicted probability and the observed outcome. Lower scores indicate better probabilistic forecasting because they reward assigning high probability only when justified and penalise unwarranted certainty. [Wikipedia]WikipediaBrier scoreBrier score
The Brier score is known as a proper scoring rule, meaning that the mathematically optimal strategy is to report your genuine probability estimate rather than exaggerating or hedging. This property makes it especially useful for improving judgement because it discourages gaming the feedback system. [Wikipedia]WikipediaBrier scoreBrier score

What forecasting tournaments have shown
Large forecasting tournaments provide unusually strong evidence because participants make hundreds of probability forecasts before outcomes are known.
The most influential example is the Good Judgment Project, which studied thousands of forecasters making geopolitical predictions over several years. Rather than evaluating isolated predictions, researchers tracked probability estimates using scoring rules such as the Brier score.
Several findings stand out:
- Training people to think probabilistically produced measurable improvements in forecasting accuracy.
- The best performers continually updated probabilities as new evidence appeared rather than defending their initial views.
- Performance remained relatively stable across many questions, suggesting that good probabilistic judgement is a learnable skill rather than repeated luck.
- Teams of skilled forecasters, combined using statistical aggregation, often outperformed even the strongest individuals. [Wikipedia+3ResearchGate+3Good Judgment]researchgate.netResearchGate(PDF) Identifying and Cultivating Superforecasters as a…25 May 2015 — Across a wide range of tasks, research has shown tha…
Importantly, these studies evaluated hundreds of forecasts per person. Their conclusions depended on repeated, scoreable confidence estimates rather than memorable successes or failures.
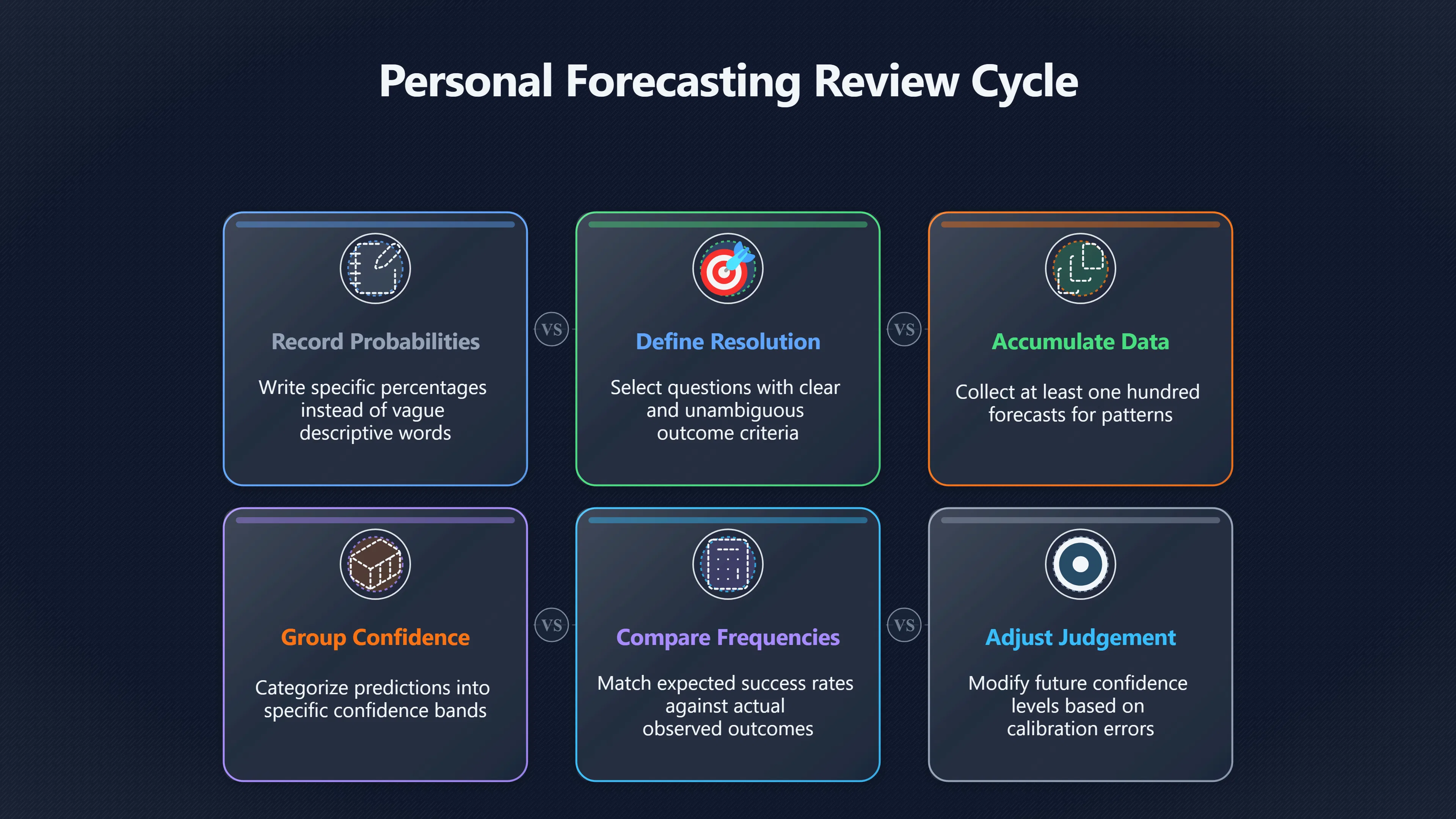
Simple ways to review batches of predictions
A useful personal forecasting system does not require specialised software. The key is to create repeated opportunities for calibration.
A straightforward review cycle includes:
- Record probabilities before the outcome. Write “65%” or “80%”, not simply “likely”.
- Choose questions with clear resolution criteria. Ambiguous outcomes weaken feedback.
- Accumulate enough predictions. Twenty forecasts reveal little; one hundred begin to show meaningful patterns.
- Group forecasts into confidence ranges. For example, compare all predictions between 60–69%, 70–79% and 80–89%.
- Compare expected and observed frequencies. If predictions in the 80–89% range succeed only about 60% of the time, confidence is too high.
- Adjust future confidence rather than merely celebrating correct answers.
This approach shifts attention away from individual wins and losses towards long-run judgement quality. The question becomes not “Was I right?” but “Did my confidence accurately reflect reality?”

Common mistakes when using probabilities
People new to probabilistic forecasting often make predictable errors.
Treating probabilities as guarantees. A 90% forecast still fails occasionally. Calibration concerns long-run frequencies, not certainty in individual cases.
Avoiding extreme probabilities. Some people never predict above 70% or below 30%, even when evidence is overwhelming. This produces chronic underconfidence.
Using percentages casually. Assigning numbers without distinguishing between 55% and 85% removes the main benefit of probabilistic thinking.
Judging calibration from a handful of forecasts. Random variation dominates small samples. Reliable feedback requires many independent predictions.
Confusing calibration with usefulness. A forecaster who predicts 50% for everything may appear reasonably calibrated over time but offers little practical value because they fail to separate likely from unlikely outcomes. Proper scoring rules therefore reward both accurate confidence and informative discrimination. [arXiv+2Wikipedia]arxiv.orgarXiv"Calibeating": Beating Forecasters at Their Own GameSeptember 11, 2022…
Why saying “70%” changes how you think
Assigning an explicit probability forces a different style of reasoning. Instead of asking whether a claim feels convincing, you must consider what evidence would justify moving from 60% to 70%, or from 70% to 85%.
That discipline creates a feedback loop unavailable with vague language. After enough forecasts, your numerical confidence develops a measurable track record. Overconfidence, excessive caution and genuine expertise become visible because each can be compared against reality across repeated judgements.
For anyone trying to improve analytical skill, that is the central advantage of probabilistic forecasting. Confidence stops being an impression and becomes evidence that can be scored, reviewed and gradually calibrated.
Amazon book picks
Further Reading
Books and field guides related to Why Saying 70 Percent Changes Feedback. Use these as the next step if you want deeper reading beyond the article.
The Signal and the Noise
Directly explains probabilistic forecasting, calibration, feedback, and improving prediction accuracy.
Thinking in Bets
Encourages probabilistic thinking and separating confidence from outcomes.
How to Measure Anything
Shows how uncertainty can be quantified and measured using probabilistic methods.
The Black Swan
Provides important context on uncertainty, overconfidence, and limits of prediction.
eBay marketplace picks
Marketplace Samples
Live-tested eBay searches with available results related to this page.



Endnotes
-
Source: researchgate.net
Link: https://www.researchgate.net/publication/277087515_Identifying_and_Cultivating_Superforecasters_as_a_Method_of_Improving_Probabilistic_PredictionsSource snippet
ResearchGate(PDF) Identifying and Cultivating Superforecasters as a...25 May 2015 — Across a wide range of tasks, research has shown tha...
Published: May 2015
-
Source: Wikipedia
Title: Brier score
Link: https://en.wikipedia.org/wiki/Brier_score -
Source: arxiv.org
Title: arXiv”Calibeating”: Beating Forecasters at Their Own Game
Link: https://arxiv.org/abs/2209.04892Source snippet
September 11, 2022...
Published: September 11, 2022
-
Source: Wikipedia
Title: Philip E. Tetlock
Link: https://en.wikipedia.org/wiki/Philip_E._Tetlock -
Source: arxiv.org
Title: arXiv Metrics of calibration for probabilistic predictions
Link: https://arxiv.org/abs/2205.09680 -
Source: Wikipedia
Title: The Good Judgment Project
Link: https://en.wikipedia.org/wiki/The_Good_Judgment_ProjectSource snippet
The Good Judgment ProjectPredictions are scored using Brier scores.... The top forecasters in GJP are "reportedly 30% better than int...
-
Source: goodjudgment.com
Title: Good Judgment Superforecaster-Accuracy.pdf
Link: https://goodjudgment.com/wp-content/uploads/2022/10/Superforecaster-Accuracy.pdfSource snippet
Good Judgment measures accuracy using the Brier score, a score that shows how far a forecast fell from the.Read more...
Additional References
-
Source: aiimpacts.org
Link: https://aiimpacts.org/evidence-on-good-forecasting-practices-from-the-good-judgment-project/Source snippet
Brier scores mean less accuracy, so negative correlations are good. “Ravens” is...Read more...
-
Source: principus.si
Title: philip tetlock dan gardner superforecasting
Link: https://principus.si/2022/11/23/philip-tetlock-dan-gardner-superforecasting/Source snippet
Philip Tetlock, Dan Gardner: Superforecasting23 Nov 2022 — At the end of the first year, Doug's overall Brier score was 0.22, putting him...
-
Source: commoncog.com
Title: how do you evaluate your own predictions
Link: https://commoncog.com/how-do-you-evaluate-your-own-predictions/Source snippet
?17 Dec 2019 — This post provides a comprehensive summary of the technique that Tetlock and Gardner presents in Superforecasting.Read more...
-
Source: pmc.ncbi.nlm.nih.gov
Link: https://pmc.ncbi.nlm.nih.gov/articles/PMC10189590/Source snippet
improves forecasting - PMC - NIHby DN Ferreiro · 2023 · Cited by 4 — Because higher Brier scores indicate lower prediction accuracy we re...
-
Source: youtube.com
Title: Superforecasting by Philip E. Tetlock: 7 Minute
Link: https://www.youtube.com/watch?v=IZ8b_fAVFnwSource snippet
How Accurate are Weather Forecasts, Anyway? | SDG Decision Education Center...
-
Source: youtube.com
Title: Improve Your Decision-Making with Your Own Brier Score
Link: https://www.youtube.com/watch?v=sL39bKyHcLISource snippet
Superforecasting by Philip E. Tetlock: 7 Minute Summary...
-
Source: youtube.com
Title: Model Calibration
Link: https://www.youtube.com/watch?v=BiaebXlgfNQSource snippet
Why Predictions Fail | Use Probabilities Instead of Certainty...
-
Source: forum.effectivealtruism.org
Link: https://forum.effectivealtruism.org/posts/pnpnqA4hijnr59p7d/efforts-to-improve-the-accuracy-of-our-judgments-andSource snippet
In one...Read more...
-
Source: youtube.com
Title: How Accurate are Weather Forecasts, Anyway? | SDG Decision Education Center
Link: https://www.youtube.com/watch?v=jXnaN0k6oYo
Topic Tree